
6.1. Initial Value Problem I. First Order ODE.#
In this section, we consider a dynamical variable \(\mathbf{x}(t)\), which is a function of a single parameter \(t\). The parameter \(t\) can be any single parameter. In physics, however, it usually represents time. Hence, we shall call \(t\) time in this section. The variable \(\mathbf{x}\) can be scalar, vector, or a collection of any real valued quantities. (For complex quantities, real and imaginary parts can be treated as two independent variables.) The position and momentum of a particle are such dynamical variables.
The dynamical variable usually satisfies a certain ordinary differential equation (ODE). We are interested in finding a particular evolution of the variable for \(t_\text{fin} \ge t \ge t_\text{ini}\) by solving the ODE, where \(t_\text{ini}\) and \(t_\text{fin}\) are initial and final time. To solve it, we need a particular value of the variable at a given time. Typically, we are given an initial value \(\mathbf{x}(t_\text{ini})\) and thus this kind of mathematical problem is called initial value problem.
We begin with first-order ODEs expressed in a standard form:
where \(\mathbf{F}\) is a given function of \(\mathbf{x}\) and \(t\). Second order ODEs are discussed in the next section.
6.1.1. First Order ODEs#
For simplicity, we focus on the first order ODE of a single scalar variable \(x\) for a while. Multivariable cases will be discussed in the later subsections. More specifically, we want to solve the following type of ODE:
for a given function \(F(x,t)\) and an initial condition \(x(t_0)\) . The exact solution is a continuous function \(x(t)\) for a time period from an initial time \(t_\text{ini}\) to a final time \(t_\text{fin}\). However, in the computer we work with discrete time \(t_n = t_\text{ini} + n h,\, n=0, \cdots, N\) where \(h\) is a time step defined by \(h=\displaystyle\frac{t_\text{fin}-t_\text{ini}}{N}\). The numerical solution is expressed as a sequence \(x(t_0), x(t_1), x(t_2), \cdots, x(t_N)\). (Notice that \(t_0=t_\text{ini}\)) For convenience, we introduce shorthand expression \(x_{n} \equiv x(t_n)\) and also \(F_n = F(x_n,t_n)\). Our goal is to develop numerical algorithms to predict \(x_{n+1})\) knowing the previous points \(\{x_0,\cdots,x_n\}\). We can construct the whole sequence by repeating the procedure recursively starting from \(x_0\).
While there are a variety of approaches to solve the ODE (6.1), we adopt a most popular approach based on Taylor expansion:
Other approaches usually reach the identical or similar algorithms. We shall discuss the graphcal interpretation for individual algorithms.
We rewrite the ODE in a different mathematical form suitable for the development of numerical methods. The basic idea is to construct a recursive equation. There are two common approaches, one based on the mean value theorem and the other on integral equation. The mean value theorem states that there exist \(c\) in \((a,b)\) such that \(f'(c) = \displaystyle\frac{f(b)-f(a)}{b-a}\) where \(f'(x) = \frac{d f}{d x}\). Applying it to our problem, there exists \(s \in (t_n,t_{n+1})\) such that
from which we write the future point \(x_{n+1}\) as
This equation is still not computable since we don’t know the value of \(s\) and \(x(s)\) in the right hand side. We need to invent an approximation to estimate \(F(x(s),s)\). The second approach is to rewrite the ODE in a form of integral. Integrating the both sides of the ODE, we obtain
which is another exact relation. To carry out the integral we need to know \(x(s)\) but it is the solution of the ODE we are tying to find. Therefore, we need a method to approximately estimate the integral without the knowledge of \(x(s)\).
The two expressions, (6.4) and (6.5), are mathematically equivalent since there is \(s \in (t_n,t_{n+1})\) such that \(\int_{a}^{b} f(x) dx = (b-a) f(s)\). At the end the both approaches reach the same outcome. However, the two approaches provide different visual interpretations. Looking at the same problem from two different views may help us to develop a better approximation for a higher accuracy. In either approach, we construct a recursive equation and we obtain the solution \(x(t_0), x(t_1), x(t_2), \cdots, x(t_N)\) one by one recursively. To do so, we must find a good estimate of \(F\left[x(t),t\right]\) for the interval \((t_n,t_{n+1})\).
6.1.1.1. Euler method#
We being with the simplest method which may not be useful in practical applications but gives us some idea of how numerical integration of an ODE works. Consider the Tayler expansion (6.2). If \(h\) is small enough, we can ingnore the terms of order $h^2^ and higher, then we have
Using the ODE, we replace \(\dot{x}(t_n)\) with \(F(x(t_n),t_n)\) which leads to a recursive equation
where \(\mathcal{O}(h^2)\) ignored. The recursive equation is known as the Euler rule . The visual interpretation of the Euler method is quite simple. First we assumes that the curve \(x(t)\) is approximately a straight line between \(t_n\) and \(t_{n+1}\). The slope of the curve is unknown except at \(t_n\). So, we just use \(\dot{x}(t_n) = F_n\) as the slope. (See the right panel of Fig. 6.1.) We further justify the Euler method using the forward finite difference approximation of derivative (Section 3.1). Substituting the forward finite difference method, \(\dot{x}(t_n) = (x_(t_n+h)-x(t_n))/h\) to the ODE, we obtain (6.6). Hence the Euler method is equivalent to use the forward finite difference method to evaluate the derivative in the ODE. From the prospect of Eq. (6.4), the unknown \(s\) is replaced with \(t_n\), which is exactly the forward finite difference method. In (6.5), the integral is approximated by the rectangular rule (Section 5.1) as illustrated in the left panel of Fig. 6.1.
To get the whole sequence \(\{x_n\}\) starting from the initial value, \(x_0\), we first evaluate \(F_0=F(x_0,t_0)\). Then, \(x_1\) is predicted by Eq. (6.6). Using this procedure recursively, we obtain the whole sequence from \(x_0\) to \(x_N\). This method is known as the Euler method.
Earlier, we learned that neither the forward finite different method nor the rectangular rule is accurate enough in practical applications. Therefore, we don’t expect that the Euler method is a good method. From the Tayler exapansion, the order of error is \(h^2\) for each step. After \(N\) iteration, the global error becomes \(N \mathcal{O}(h^2) \sim \mathcal{O}(h)\). We hope that this is a good approximation with a sufficiently small \(h\). However, the order \(h\) of error is not acceptable and thus the Euler method is not good enough in practice.
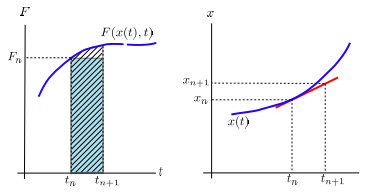
Fig. 6.1 Illustration of the Euler method. Left: The blue line represents the integrand of Eq. (6.5) which is unknown to us. Assuming that \(F_n\) is on the exact curve, we approximate the integral (the shaded area) by the rectangular rule (the area of the blue rectangle) discussed in Section 5.1. The unaccounted area is proportional to \(h^2\). Right: Using the slope of the curve at \(t_n\), we extrapolate next point \(x_{n+1}\) assuming the curve is close to the straight line (red line). This is equivalent to use the forward finite difference method of the first order derivative discussed in Section 3.1. Note that even if \(x_n\) is on the exact curve, \(x_{n+1}\) is not. The error is clearly visible.#
Algorithm 6.1.1: Euler method
Set the total period \(T\) and the number of steps \(N\)
Calculate the step size \(h=\displaystyle\frac{T}{N}\).
Set the initial condition \(x_0\) and \(t_0=0\).
Starting with \(n=0\), repeat the following \(N\) times
Evaluate the function \(F_n=F(x_n,t_n)\).
Calculate a new point \(x_{n+1}=x_n+F_n h\).
Increment the step: \(n=n+1\).
6.1.1.2. Predictor-Corrector Method#
One way to raise the accuracy of the Euler method is to use a more accurate slope. Consider another Taylor expansion around \(t_{n+1}\) with the negative step \(-h\):
Subtract Eq. (6.7) from Eq. (6.2) and rearrange the result, we find
where we used \(\ddot{x}(t_n) - \ddot{x}(t_{n+1}) \sim \mathcal{O}(h)\). Replacing \(\dot{x}\) with \(F(x,t)\), we obtain a relation similar to the Euler rule (6.6):
Comparing this equation with the Euler rule (6.6), the slope \(F_n\) is replaced with the average of the current slope \(F_n\) and future slope \(F_{n+1}\) (the right panel of Fig. 6.2. The order of error is \(h^3\), better than \(h^2\) of the Euler method.
From the view of (6.9), the right hand side is replaced by the average:
Similarly, we can improve the accuracy of the integral in (6.5) by using the trapezoidal rule instead of the rectangular rule (see the left panel of Fig. 6.2):
In either approach, we obtain the same relation (6.8).
Unlike the Euler rule (6.6), Eq. (6.8) is implicit since the both sides contain future point \(x_{n+1}\). Solving it for \(x_{n+1}\) is not a trivial task. A common approach is the following iterative method. First we guess the solution, which we denote as \(x^{(0)}_{n+1}\). Using it in the right hand side of (6.8), we obtain a new prediction \(x^{(1)}_{n+1}\). Then, plug it in the right hand side again, we get another prediction \(x^{(2)}_{n+1}\). By repeating this procedure, the difference between the input and the output becomes negligible after a certain number of iterations, that is \(x^{(k+1)}_{n+1} \approx x^{(k)}_{n+1}\). We say that the input and the output is now self-consistent. We can stop the iteration when a desired accuracy is achieved. The iterative method is not stable and can go wrong after many iterations. There are ways to stabilize the iteration which we will discuss in a later chapter.
To apply the iterative method to the our problem, we use the Euler rule to get the good first guess: \(x^{(0)}_{n+1} = x_n + F_n h\). The output of the first iteration is
If the output is not accurate enough, we go to the next round. Since (6.8) is valid only at the order of \(h^3\), we don’t have to iterate the procedure many times. Anything better than the Euler rule is good enough. Hence, no further iteration is necessary in the current approximation. Now, we have a future point \(x^{(1)}_{n+1}\), which is better than the Euler rule.
In summary, we predict \(x_{n+1}\) using the Euler method. Let the first slope \(k_1 = F(x_n,t_n)\). Then, \(x^{(0)}_{n+1} = x_n + k_1 h\). At the second step, we evaluate the second slope \(k_2 = F(x^{(0)}_{n+1},t_{n+1}) = F(x_n + k_1 h, t_n)\) . Then correct \(x^{(0)}_{n+1}\) using the second slope by Eq. (6.8). The new \(x_{n+1}\) is given by
This is the “predictor-corrector” method. The order of error at each step is determined by the trapezoidal rule, that is \(\mathcal{O}(h^3)\). Thus the overall error is \(N \mathcal{O}(h^3) \sim \mathcal{O}(h^2)\).
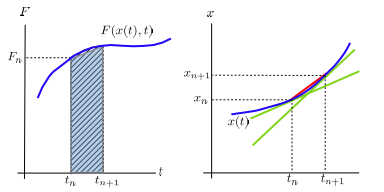
Fig. 6.2 Illustration of the predictor-corrector method. Left: The blue line represents the integrand of Eq. (6.5), which is unknown to us. Assuming that we know both \(F(x(t_n),t_n)\) and \(F(x(t_{n+1}),t_{n+1})\), we approximate the integral by the trapezoidal rule discussed in Section 5.1. The unaccounted area is proportional to \(h^2\). Right: Using the two slopes (two green lines) \(\dot{x}_n = F(x(t_n),t_n)\) and \(\dot{x}_{n+1} = F(x(t_{n+1}),t_{n+1})\), we approximate \(\dot{x}(t)\) with the average of the two slopes. This is equivalent to use the mean finite difference method of the first order derivative discussed in Section 3.1.#
Algorithm 6.1.2: Predictor-corrector method
Set the total period \(T\) and the number of steps \(N\)
Calculate the step size \(h=\displaystyle\frac{T}{N}\).
Set the initial condition \(x_0\) and \(t_0=0\).
Starting with \(n=0\), repeat the following \(N\) times
first slope: \(k_1 = F(x_n,t_n)\)
predictor: \(x_{n+1} = x_n + k_1 h\).
second slope: \(k_2 = F(x_{n+1},t_{n+1})\).
corrector: \(x_{n+1}=x_n + \displaystyle\frac{h}{2} \left ( k_1 + k_2 \right )\).
Increment the step: \(n=n+1\).
Example 6.1.1
A particle of mass \(m\) is dropped from rest under a uniform gravity \(g\). The drag force due to the presence of air is \(-\gamma v\) where \(v\) is velocity and \(\gamma\) the frictional coefficient. The equation of motion is given by the Newton equation:
and its solution with the initial condition \(v(0)=0\) is given by
where \(-m g /\gamma\) is the terminal velocity.
Let us integrate the Newton equations using Euler and Predictor-Corrector methods and compare the results with the exact solution. We integrate from \(t=0\) to \(t=10\) using the step size \(h=0.01\). As usual, we simplify the mathematical expression by normalizing quantities and reduce the number of parameters. By normalizing the time as \(\tau =\gamma t/m\) and introducing a new constant \(\xi = m g \gamma\), Eq. (6.12) becomes \(\dot{v} = -v + \xi\) where \(\dot{v} = \frac{dv}{d\tau}\). Now, we have only one parameter \(\xi\) and the terminal velocity is given by \(-\xi\).
import numpy as np
import matplotlib.pyplot as plt
# parameter
g=10.0
# integration parameters
tmax=10. # maximum time
N=1000 # maximum steps
h=tmax/N # time step
# set arrays
v_ex=np.zeros(N+1)
v_eu=np.zeros(N+1)
v_pc=np.zeros(N+1)
t=np.linspace(0,N,N+1)*h
# intial condition
v_ex[0]=0.0
v_eu[0]=0.0
v_pc[0]=0.0
for i in range(0,N):
# Euler method
F = -v_eu[i] - g
v_eu[i+1] = v_eu[i] + F*h
# Predictor-Corrector method
F= -v_pc[i] - g
v_pc[i+1] = v_pc[i] + F*h; # predictor
F = -(v_pc[i]+v_pc[i+1])/2 - g
v_pc[i+1] = v_pc[i] + F*h # corrector
# Exact solution
v_ex[i+1] = g*(np.exp(-t[i+1])-1)
plt.ioff()
plt.figure(figsize=(10,4))
# Plot the solutions
plt.subplot(1,2,1);
plt.axhline(y = -g, color = '0.8', linestyle = '--')
plt.plot(t,v_ex,'-k',label='Exact')
plt.plot(t,v_eu,'-b',label='Euler')
plt.plot(t,v_pc,':r',label='Predictor-Corrector')
plt.xlabel('t')
plt.ylabel('v(t)')
plt.legend(loc=1)
# Plot the absolute errors
plt.subplot(1,2,2)
plt.semilogy(t,abs(v_eu-v_ex),'-b',label='Euler')
plt.semilogy(t,abs(v_pc-v_ex),'-r',label='Predictor-Corrector')
plt.xlabel('t')
plt.ylabel('absolute error')
plt.legend(loc=1)
plt.show()
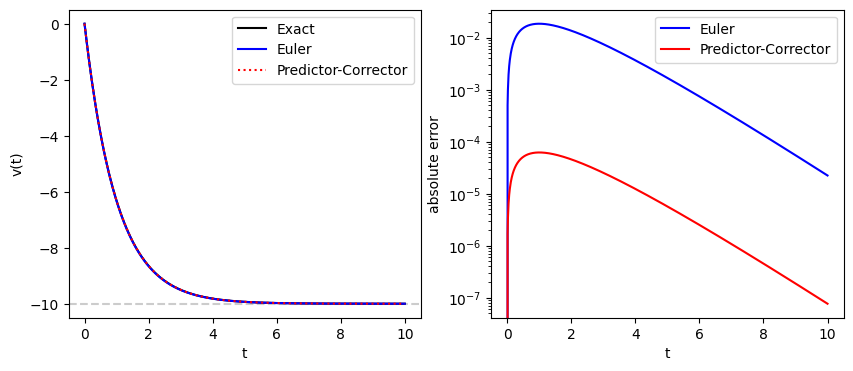
The left plots show that the trajectories of the two numerical methods agree with the exact trajectory at least in he naked eyes. The right panel plots the absolute errors. The predictor-corrector method is significantly better than the Euler method.
6.1.1.3. 2nd-order Runge-Kutta Method#
The Runge-Kutta (RK) developed a systematic way to improve the accuracy of the numerical integration of ODEs based on the Taylor expansion. FOr the second order RUnge-Kutta method, we write a recursive equation in the following form:
where
We want to make the approximation accurate up to the order of \(h^2\). That is we neglect the order of \(h^3\) and higher. It is clear that \(k_1\) is exactly at the order of \(h\) and thus no approximation is needed. On the other hand, \(k_2\) has higher order terms since \(F\) in the right hand side of EQ. (6.14) contains \(h\). Expanding in Taylor series, EQ. (6.14) can be expressed as
Plug \(k_1\) and \( k_2\) in to EQeq:k1+k2_RK2, we find the recursive equation
Now, compare this with the direct calculation of Taylor expansion (6.2), we find that \(\alpha\) and \(\beta\) must satisfy the following equation:
Since there are only three equations for four unknowns, the solution is not unique and there are infinitely many solutions.. We can find immediately \(a=b=\frac{1}{2}, \alpha=\beta=1\) satisfies the equation. This nothing but the predictor-corrector method. Anther simple solution is \(a=0, b=1, \alpha=\beta=\frac{1}{2}\), which is known as midpoint method. A slightly odd solution known as Ralston’s Method is given by \(a=\frac{1}{3}, b=\frac{2}{3}, \alpha=\beta=\frac{3}{4}\). All these solutions give the same order of accuracy.
Fig. 6.3 Illustration of the predictor-corrector method. Left: The blue line represents the integrand of Eq. (6.5), which is unknown to us. Assuming that we know both \(F(x(t_n),t_n)\) and \(F(x(t_{n+1}),t_{n+1})\), we approximate the integral by the trapezoidal rule discussed in Section 5.1. The unaccounted area is proportional to \(h^2\). Right: Using the two slopes (two green lines) \(\dot{x}_n = F(x(t_n),t_n)\) and \(\dot{x}_{n+1} = F(x(t_{n+1}),t_{n+1})\), we approximate \(\dot{x}(t)\) with the average of the two slopes. This is equivalent to use the mean finite difference method of the first order derivative discussed in Section 3.1.#
Algorithm 6.1.2: 2nd-order Runge-Kutta method
Set the total period \(T\) and the number of steps \(N\)
Calculate the step size \(h=\displaystyle\frac{T}{N}\).
Set the initial condition \(x_0\) and \(t_0=0\).
Starting with \(n=0\), repeat the following \(N\) times
Predictor: \(k_1 = F(x_n,t_n)\)
Corrector: \(k_2 = F(x_n+k_1 h/2,t_{n}+h/2)\).
New point: \(x_{n+1}=x_n + k_2 h\).
Increment the step: \(n=n+1\).
6.1.1.4. 4th-Order Runge-Kutta Method#
The Runge-Kutta approach allows us to systematically improve the accuracy. The second RK method evaluate \(F(x,t)\), twice per step. Now consider a RK method that evaluate it four times per step, which is known as the 4th order RK method. The method is highly accurate and widely used in real applications. Since the rigorous derivation of this formula is a bit complicated, we introduce it based on a heuristic consideration.
In order to further improve the accuracy, we use a better numerical integration method, the Simpson rule:
We learned that the Simpson rule is highly accurate. However, in order to take the advantage, we must carefully evaluate \(F_{n+1/2}\) and \(F_{n+1}\) to keep the high level of accuracy. Recalling that the high accuracy of the Simpson rule is due to the symmetric treatment of intervals \([t_n,t_{n+1/2}]\) and \([t_{n+1/2},t_{n+1}]\) so that errors in the two interval cancel out. (See Sec. Section 5.1.) The key point is how to evaluate the mid point \(x_{n+1/2}\). As usual, we begin with the Euler method in which we predict \(x_{n+1/2}\) using the slope \(k_1 \equiv F(x_n,t_n)\).
If the curve \(x(t)\) is concave (convex), the Euler method over-(under-)estimate \(x_{n+1/2}\). Now we try to correct the error using the slope at \(t_N{n+1/2}\), that is \(k_2\).
Knowing that \(k_2<k_1\) for concave curve and \(k_2 < k_1\) for convex curve, the direction of error in \(F_{n+1/2}^{(1)}\) is opposite to that in \(F_{n+1/2}^{(0)}\). The average of the two predictions cancels their errors. Now, we have a much better approximation
Using the midpoint formula we obtain
It turns out that
is good enough.
Substituting (6.18) and (6.20) to (6.15) we obtain the 4th-order Runge-Kutta method
Algorithm 6.1.2: 2nd-order Runge-Kutta method
Set the total period \(T\) and the number of steps \(N\).
Calculate the step size \(h=\displaystyle\frac{T}{N}\).
Set the initial condition \(x_0\) and \(t_0\).
Reset the counter: \(n=0\).
Repeat the following \(N\) times.
Increment time: \(t_{n+1}=t_0 + (n+1)h\).
Slope at \(t_n\): \(k_1 = F(x_n,t_n)\)
Slope at \(t_{n+1/2}\) (1st try): \(k_2 = F(x_n + \frac{k_1 h}{2}, t_n + \frac{h}{2} )\).
Slope at \(t_{n+1/2}\) (2nd try): \(k_3 = F(x_n + \frac{k_2 h}{2}, t_n + \frac{h}{2} )\).
Slope at \(t_{n+1}\): \(k_4 = F(x_n + k_3 h, t_n + h) \).
4th order Runge-Kutta step: \(x_n +\displaystyle\frac{h}{6} ( k_1 + 2 k_2 + 2 k_3 + k_4 )\).
Increment the step: \(n=n+1\).
Example 6.1.2 In Example 6.1.1, we found that the predictor-corrector method is more accurate than the Euler method. For cpmparison, we solve the same problem with 2nd and 4th order Runge-Kutta methods.
import numpy as np
import matplotlib.pyplot as plt
# system parameters
gamma=1.0
g=9.8
m=1.0
# integration parameters
tmax=10 # maximum time
N=1000 # maximum steps
h=tmax/N # time step
# set arrays
v_rk2=np.zeros(N+1)
v_rk4=np.zeros(N+1)
v_ex=np.zeros(N+1)
t=np.linspace(0,N,N+1)*h
for i in range(0,N):
# Runge-Kutta 2nd order
k1 = -gamma*v_rk2[i]/m - g
v_mid = v_rk2[i] + k1*h/2.0
k2 = -gamma*v_mid/m - g
v_rk2[i+1] = v_rk2[i] + k2*h
# RUnge-Kutta 4th order
k1 = -gamma*v_rk4[i]/m - g
v_mid = v_rk4[i] + k1*h/2.0
k2 = -gamma*v_mid/m - g
v_mid = v_rk4[i] + k2*h/2
k3 = -gamma*v_mid/m - g
v_end = v_rk4[i] + k3*h
k4 = -gamma*v_end/m - g
v_rk4[i+1] = v_rk4[i] + (k1+2*(k2+k3)+k4)*h/6.0
# Exact solution
v_ex[i+1] = m*g/gamma*(np.exp(-gamma*t[i+1])-1)
plt.ioff()
plt.figure(figsize=(12,5))
# Plot the solutions
plt.subplot(1,2,1);
plt.axhline(y = -g, color = '0.8', linestyle = '--')
plt.plot(t,v_ex,'-k',label='Exact')
plt.plot(t,v_rk2,'-b',label='RK2')
plt.plot(t,v_rk4,':r',label='RK4')
plt.xlabel('t')
plt.ylabel('v(t)')
plt.legend(loc=1)
# Plot the absolute errors
plt.subplot(1,2,2)
plt.semilogy(t,abs(v_rk2-v_ex),'-b',label='RK2')
plt.semilogy(t,abs(v_rk4-v_ex),'-r',label='RK4')
plt.xlabel('t')
plt.ylabel('absolute error')
plt.legend(loc=1)
plt.show()
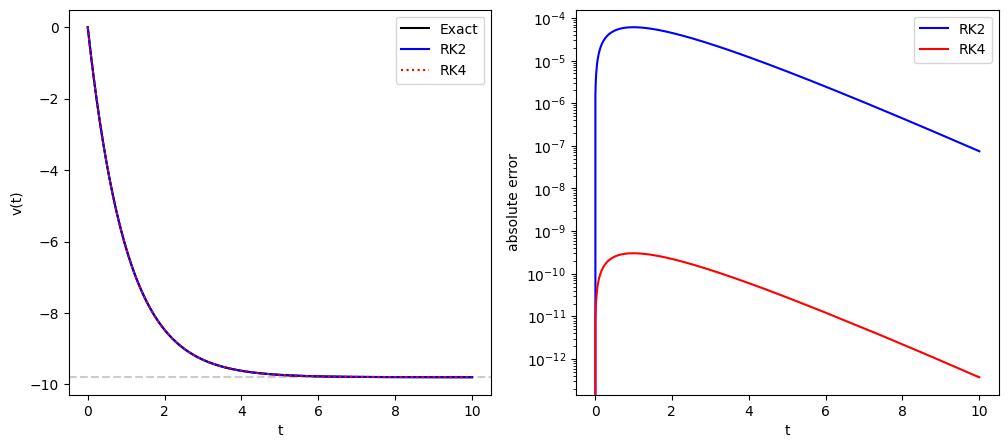
The outcomes of both the 2nd and 4th order RK methods agree with the exact solution as the left panel shows. The right panel shows that while the error of the 2nd order RK method is comparable to that of the predictor corrector method.he absolute errors, the error of the 4th order RK method is far more accurate fi the same step size is used.
6.1.1.5. Adaptive Step: Runge-Kutta-Fehlberg Method#
The solution to an ODE can be slowly changing in some parts and rapidly varying in other parts. If a constant step \(h\) were used, it must be small enough for the rapid change. However, such a small \(h\) is not necessary in the slowly changing region and thus we waste computer time. Furthermore, finding an appropriate step size becomes difficult if we don’t know the rapidly changing part prior to the calculation. It is desired to have an algorithm which automatically adjusts the step size as the solution is computed. Runge-Kutta-Felberg method which is also known as RK45 finds appropriate step size so that the result is accurate to the given tolerance.
Like regular Runge-Kutta methods, we try to find solution \(x_{n+1}\) at \(t_{n+1}\) knowing the previous step \(x_n\) at \(t_n\) where \(t_{n+1}= t_{n}+h\). Here we show the algorithm without proof. For a given \(h\), we evaluate the following six quantities,
Using four points (\(k_1\), \(k_3\), \(k_4\), and \(k_5\)), we make a first prediction:
The second prediction, which uses more points (\(k_1\), \(k_3\), \(k_4\), \(k_5\), and \(k6\)), i sgiven by
The second prediction is more accurate than the first one. Now, we estimate the error by
If \(\delta < \text{tol}\) (where tol is a tolerance), then we accept \(x_{n+1}^\prime\) as a good solution and moves to the next step.
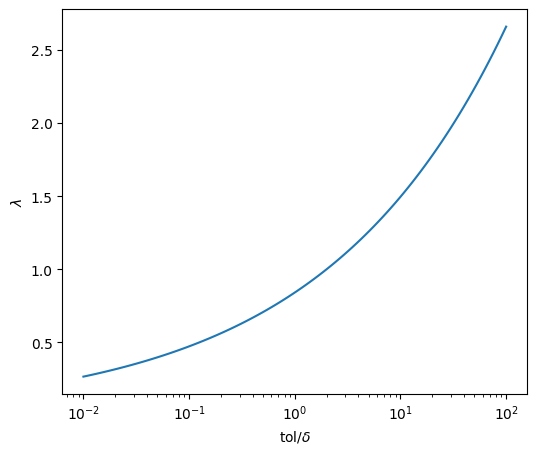
In this case, the current step size \(h\) is clearly small enough. If \(\delta \ll \text{tol}\), perhaps, \(h\) is too small. To save computing time, we may want to use a larger step size in the next step, \(h_\text{new} = \lambda h_\text{old}\) where
$\( \lambda =\left ( \frac{\text{tol}}{2 \delta} \right )^{1/4}. \)$(eq:rk45_new_step)
When the error was much smaller than the tolerance, that is \(\delta \ll \text{tol}\), \(\lambda \gg 1\) and thus \(h\) increases significantly. On the other hand, if the error barely smaller than the tolerance, (\(\delta \approx 1\)), then \(\lambda \approx 0.84\) and thus \(h_\text{new}\) is lightly smaller than \(h_\text{old}\) to improve the accuracy.
If \(\delta > \text{tol}\), the prediction is not accurate enough and we need to recalculate the current step with a smaller \(h\). In this case, \(\lambda < 0.84\), \(h_\text{new} < h_\text{old}\) and thus the new prediction should be more accurate. WE repeat this procedure until the error becomes smaller than the tolerance.
In the following the factor \(\lambda\) is plotted as a function of \(\text{tol}/\delta\). Even when the error is large, \(h\) changes only gradually.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-2,2,100)
r = 10**x
l = (0.5*r)**(1./4.)
plt.figure(figsize=(6,5))
plt.semilogx(r,l)
plt.xlabel(r"tol/$\delta$")
plt.ylabel(r"$\lambda$")
plt.show()
Example 6.1.3 In Example 6.1.2, we found the 4th order RK was remarkably accurate. However, the accuracy was unnecessarily high. We could use a larger step size. Here , we solve the same free falling problem again using the RK45 method. The aim of this example is how \(h\) is adjusted to keep the accuracy smaller but also close to the tolerance. For that purpose, we use a canned routine RK45 in the scipy package. It is easier to call RK45 through a wrapper function solve_ivp.
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def F(t,v):
# system parameters
gamma=1.0
m=1.0
g=9.8
a = -gamma*v/m - g
return a
t0 = 0 # initial time
v0 = [0] # initial velocity
tspan = [0,10] # maximum time
h0=1
rtol=1e-5
sol=solve_ivp(F,tspan,v0,method='RK45',rtol=rtol,first_step=h0)
t=sol.t
v=list(sol.y.flat)
# exact solution
v_ex=m*g/gamma * (np.exp(-gamma*t)-1)
n=len(t)
h=t[1:n-1]-t[0:n-2]
hmin=min(h)
hmax=max(h)
print(" the smallest h = {0:8.5f}".format(hmin))
print(" the largest h = {0:8.5f}".format(hmax))
plt.ioff()
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.plot(t,v,'or',label="RK45")
plt.plot(t,v_ex,'-k',label="Exact")
plt.plot(t,t*0,'ob',label="Time step")
plt.xlabel('t')
plt.ylabel('velocity')
plt.legend(loc=0)
plt.subplot(1,2,2)
plt.semilogy(t,abs(v-v_ex),'-k')
plt.xlabel('t')
plt.ylabel("absolute error")
plt.show()
the smallest h = 0.27858
the largest h = 1.39575
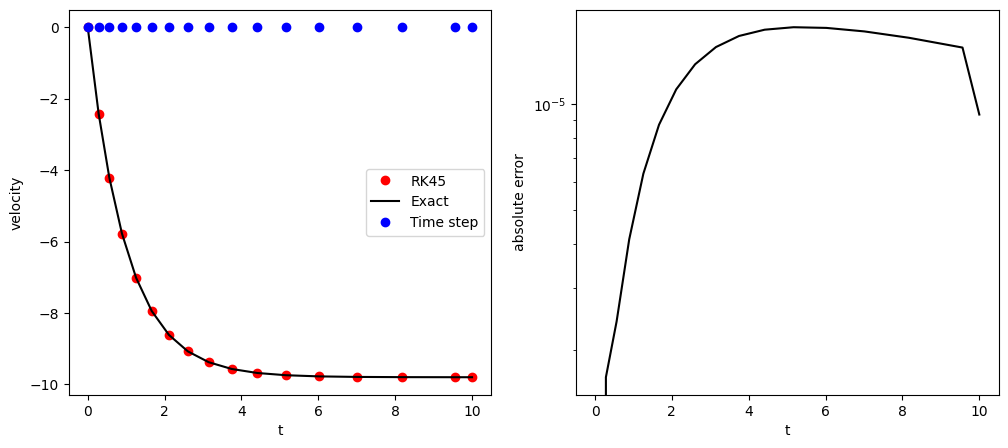
The blue dots in the left panel show the actual time \(t_n\). The initial step size is intentionally set to be large \(h=1.0\) but the RK45 automatically reduced it until the tolerance (\(10^{-5}\)) is satisfied. The smallest step length used by RK45 is \(0.27\). Notice that the gap between \(t_n\) and \(t_{n+1}\) is increasing, indicating that the step size \(h\) is increasing. The velocity changes rapidly at the beginning and thus a small step size is needed. As the velocity approaches the terminal velocity, the step size increases gradually since the velocity is changing slowly. The largest step size was \(1.39575\), about five times larger than the smallest step. The right panel shows that the error remains close to the tolerance. (The strange behavior at the end is that time is forcibly terminated at \(t=10\). Hence, the final step size is smaller than the one estimated by RK45.